NodeJS에서 HTML을 파싱하여서 Scraping하기 위한 모듈로 Cheerio가 있습니다.
오늘은 이 모듈을 이용해서 HTML을 파싱해서 가져오는 방법에 대해서 정리해 보도록 하겠습니다.
1. Cheerio와 Request 모듈 설치
아래 코드를 터미널에 입력해서 해당 프로젝트내에서 Cheerio모듈이 설치되도록 해 줍니다.
npm install cheerio --save
이번에는 bent 모듈을 설치해 보겠습니다.
사실 예전에는 request모듈을 사용하였습니다. 그렇지만, request는 deprecated되었구요.
개발자는 bent를 새로운 프로젝트로 개발하고 있다고 하여서, bent로 작업을 해 보았습니다.
이제 설치한 모듈을 해당 파일내에서 import해 주어야 하는데요.
아래와 같이 해 주면 됩니다.
const cheerio = require('cheerio');
2. Loading
파싱을 하기위해서 제일 먼저 해야할 것은 파싱할 HTML을 loading하는 것 입니다.
아래와 같은 html이 있다고 가정해 보겠습니다.
<html>
<head>
</head>
<body>
<ul id="fruits">
<li class="apple">Apple</li>
<li class="orange">Orange</li>
<li class="pear">Pear</li>
</ul>
</body>
</html>
Loading을 하기 위해서는, require로 cheerio모듈을 불러오구요.
아래와 같이 load()를 사용해 주면 됩니다.
html()함수를 사용하면, load되었던 html이 그대로 출력됩니다.
const cheerio = require('cheerio');
const $ = cheerio.load();
$.html();
2. Selector
Cheerio에서 Html을 파싱하는 방법은 매우 쉬운데요.
그 이유는 태그를 찾을때, Jquery와 거의 동일한 문법을 사용할 수 있기 때문입니다.
Selector로 아래와 같은 문법을 사용하는데요.
태그이름은 ''"로 감싸서 바로 사용할 수 있구요.
class앞에는 "."을 붙이고, id앞에는 "#"을 붙여서 찾아주면 됩니다.
$(selector, [context], [root])
위에서 말한 것 처럼, selector는 jquery에서 사용하는 selector와 거의 동일하구요.
selector에 대해서 어떤 범위에서 검색해 갈 것인지 가르킬 필요가 있을 때,
context를 사용해서 범위를 줄여줄 수 있습니다.
예를 들면, li태그를 찾는데, html전체에서 너무나 많은 li가 있다면,
원하지 않는 태그까지 찾을수도 있게 해 줍니다.
root는 html다큐먼트를 가르키구요.
참고로, context와 root는 생략할 수 있습니다.
이번에는, 아래와 같이 간단한 ul태그와 하위의 li들로 구성된 html이 있다고 가정해 보고,
몇가지 예를 보면서 좀 더 알아보겠습니다
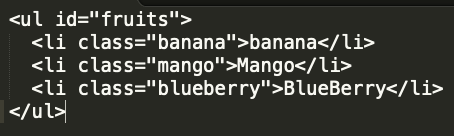
2-1. Context 사용
$('.banana', '#fruits').text()
결과: Banana
context로 fruits id를 사용하였습니다.
fruits범위안에서 banana클래스에 해당하는 것으로 검색범위를 좁혀주었습니다.
위의 예에서는 실질적으로 필요하지는 않지만, banana클래스가 여기저기서 많이 사용된다면,
필요할 수도 있겠지요.
2-2. attr 함수 사용
$('ul .mango').attr('class')
결과: mango
attr함수는 종종 쓰이는 함수인데요. attribute의 값을 가져올 수 있습니다.
위에서는 mango class attribute의 값인 mango가 결과값으로 나왔습니다.
2-3. text(), html(), val()
text(), html(), val()함수는 jquery에서도 중요하게 쓰이는 함수입니다.
역시 cheerio에서도 유용하게 쓰이는데요.
각각의 차이를 간단하게 정리해 보면 다음과 같습니다.
A. text()
text()함수는 해당하는 엘리먼트의
하위 엘리먼트들을 포함한 모든 엘리먼트들의 text들만 합쳐서 반환해 줍니다.
form태그의 inputs나 scirpts에는 사용할 수 없습니다.
이러한 태그들의 값을 가져올 때는 val()함수를 사용해야 합니다.
아래 코드의 top클래스를 text함수로 가져오면 결과는
html태그들을 제외한 텍스틀 값인
"FruitsBox Banana Mango"가 반환되어 집니다.
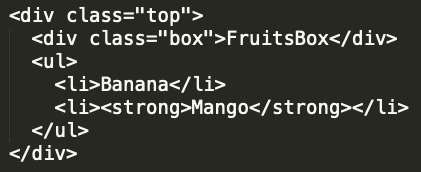
B. html()
해당하는 엘리먼트의 첫번째 엘리먼트의 html컨텐츠를 가져옵니다.
여기서 말하는 html컨텐츠란 html태그를 포함하여서 값을 반환한다는 의미입니다.
text()함수와 html태그가 포함되는지의 여부에서 차이가 발생합니다.
아래 코드에서 box클래스를 찾은다음, html()함수를 사용해 주면 반환되는 값은,
"<div class="banana">Banana</div>"이 됩니다.

scraping을 하는데 있어서는 html()보다는 text()함수를 더 많이 사용하게 될 것 같은데요.
지정한 selector로 원하는 태그를 잘 찾았는지 확인하는데 잇어서는
html()함수를 통해서 반환되는 태그들을 로그로 확인하면,
확인하는데 도움이 됩니다.
c. val()
input, select 그리고 textarea같은 form엘리먼트의 값(value)을 가져오는데 사용합니다.
$( "select#fruit" ).val();
$( "select#fruit option:checked" ).val(); //checked옵션이 선택된 드롭다운메뉴의 value를 가져옴
$( "input[type=checkbox][name=banana]:checked" ).val(); //checkbox 타입
$( "input[type=radio][name=banana]:checked" ).val();
3. Cheerio를 통해서 반환 받은 객체 사용
보통 Scraping을 하는 경우,
A태그 하위의 두개 혹은 세개의 태그로부터 값을 가져오는 경우가 많습니다.
이렇게 할 때 주의할 점은, Cheerio로부터 반환받은 Cheerio객체를
$()로 다시 쌓아줘야만 원하는 Cheerio함수의 사용이 가능하다는 것 인데요.
예를 들어 아래와 같은 코드가 있는 경우에,
$('fruits_info').children()을 array에 저장해서 사용할 텐데요.
첫번째 아이템에서 셀렉터를 이용해서 꺼내려고 할 때,
$(items[i])와 같이 Cheerio객체를 사용할 수 있도록 감싸주어야,
$(items[i]).children("name").text()와 같은 형태로 사용이 가능하다는 점을 주의해야 합니다.
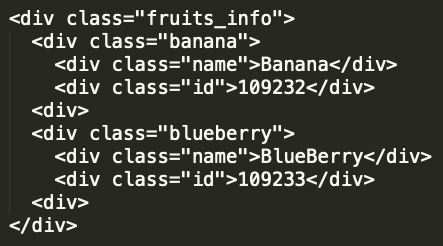
이상으로 Cheerio를 이용해서 Scraping하는 방법에 대해서 정리해 보았습니다.
Cheerio자체를 사용하는데 있어서,
request모듈에 대한 간단한 사용법도 알아야 하고,
Cheerio 셀렉터를 사용하는데 있어서 Jquery의 문법도 알아야 해서,
기본적으로 알아야 할 것들이 많이 있네요.
대신, 기존에 jquery를 사용해 보신 분들이라면 정말 쉽게 사용할 수 있을것 같습니다.
Cheerio사용과 관련해서 더 좋은 방법이 있다면 이 글을 통해서 업데이트 하도록 하겠습니다.
'NodeJS, NPM, Koa' 카테고리의 다른 글
| Dotenv 로 관리하는 환경변수 # NodeJS (0) | 2021.05.01 |
|---|---|
| Koa JS FrameWork을 이용한 RestAPI 만들기 # NodeJS (0) | 2021.05.01 |
| WebStorm NodeJS Coding Assistance 활성화 방법 (0) | 2021.04.29 |
| NodeJS Get 과 Post 의 Parameter 와 QueryString 전달 방법 (0) | 2021.04.28 |
| Babel 을 Webstorm 과 터미널 에 적용하는 방법 # Compiler ES6 (0) | 2021.04.28 |
| JWT(Json Web Token)와 세션관리에 대해서 알아보자 (0) | 2020.05.18 |
| A Record와 CNAME Record의 차이를 알아보자 (0) | 2020.04.02 |




댓글